
At some point I will write a more detailed review, but Jordynn Jack’s book Autism and Gender: From Refrigerator Mothers to Computer Geeks (University of Illinois Press, 2014) contains a thoughtful and rigorous study of the purported relationship between computer culture and Asperger’s Syndrome. Her primary focus is on popular media diagnoses of celebrated Silicon Valley entrepreneurs like Bill Gates and Mark Zuckerberg, but her larger argument about role of anecdotal evidence in framing Asperger’s as a “geek syndrome” is very relevant to the historical argument I make in both The Computer Boys book and my “Beards, Sandals, and Other Signs of Rugged Individualism” article. I wish that I had been aware of her discussion of the relationship between Simon Baron-Cohen’s work on Extreme Male Behavior and narratives about technology when I was doing my research. Although I am sure that Jordynn Jack would not define her book in terms history of technology, I hope that my fellow historians discover it. In my mind it is one of the most important contributions to our understanding of contemporary technology culture that I have read in a long while.
All posts by nathanen
 Follow
FollowThe Multiple Meanings of a Flowchart
Although I have not been posting much to this site recently, I have been busy working on my research. Most of my attention has been on a new book project tentatively entitled Dirty Bits: An Environmental History of Computing. This is a project that explores the intersection of the digital economy and the material world, from the geopolitics of minerals (lithium, cobalt, etc.) to e-waste disposal to the energy and water requirements associated with the misleadingly named “Cloud.”
But I have been continuing to work on the history of computer programming as well. My most recent article is on the history of flowcharts, which were (and to a certain extent, still are) an essential element of the process of programming. For the most of past century, learning to flowchart a problem was the first step in learning to program a computer. And yet flowcharts were rarely useful as the “blueprints” of software architecture that they were often claimed to be. Their function was much more complicated and ambiguous —although none the less useful.
In the latest issue of the journal Information & Culture, I explore the “Multiple Meanings of the Flowchart”. For those of you without access to the Project Muse academic database, you can find an earlier draft version of the paper for free online here.
Here is a brief excerpt from the introduction:
In the September 1963 issue of the data processing journal *Datamation* there appeared a curious little four-page supplement entitled “The Programmer’s Coloring Book.” This rare but delightful bit of period computer industry whimsy is full of self-deprecating (and extremely “in”) cartoons about working life of computer programmers. For example, “See the program bug. He is our friend!! Color him swell. He gives us job security.” Some of these jokes are a little dated, but most hold up surprisingly well.
One of the most insightful and revealing of “The Programmer’s Coloring Book” cartoons is also one of the most minimalistic. The drawing is of a simple program flowchart accompanied by a short and seemingly straightforward caption: “This is a flowchart. It is usually wrong.”
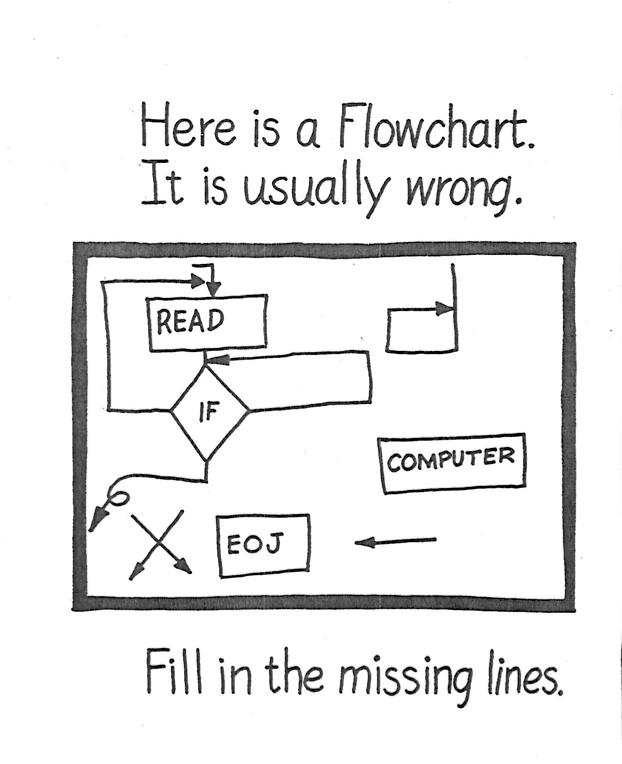
In case you don’t get the joke, here is some context: by the early 1960s, the flowchart was well-established as an essential element of any large-scale software development project. Originally introduced into computing by John von Neumann in the mid-1940s, flowcharts were a schematic representation of the logical structure of a computer program. The idea was that an analyst would examine a problem, design an algorithmic solution, and outline that algorithm in the form of a flowchart diagram. A programmer (or “coder”) would then translate that flowchart into the machine language understood by the computer. The expectation was that the flowchart would serve as the design schematic for the program code ( in the literature from this period flowcharts were widely referred to as the “programmer’s blueprint”) with the assumption was that once this “blueprint” had been developed, “the actual coding of the computer program is rather routine.”
For contemporary audiences, the centrality of the flowchart to software development would have been self-evident. Every programmer in this period would have learned how to flowchart. In the same year that the “Programmer’s Coloring Book” was published, the American Standards Association had approved a standardized flowchart symbol vocabulary. Shortly thereafter, the inclusion of flowcharting instruction in introductory programming courses had been mandated by the Association for Computing Machinery’s influential Curriculum ’68 guidelines. A 1969 IBM introduction to data processing referred to flowcharts as “an all-purpose tool” for software development and noted that “the programmer uses flowcharting in and through every part of his task.” By the early 1970s, the conventional wisdom was that “developing a program flowchart is a necessary first step in the preparation of a computer program.”
But every programmer in this period also knew that although drawing and maintaining an accurate flowchart was what programmers were *supposed* to do, this is rarely what happened in actual practice. Most programmers preferred not to bother with a flowchart, or produced their flowcharts only after they were done writing code. Many flowcharts were only superficial sketches to begin with, and were rarely updated to reflect the changing reality of a rapidly evolving software system.[@Yohe1974] Many programmers loathed and resented having to draw (and redraw) flowcharts, and the majority did not. Frederick Brooks, in his classic text on software engineering, dismissed the flowchart as an “obsolete nuisance,” “a curse,” and a “space hogging exercise in drafting.” Wayne LeBlanc lamented that despite the best efforts of programmers to “communicate the logic of routines in a more understandable form than computer language by writing flowcharts,” many flowcharts “more closely resemble confusing road maps than the easily understood pictorial representations they should be.” Donald Knuth argued that not only were flowcharts time-consuming to create and expensive to maintain, but that they were generally rendered obsolete almost immediately. In any active software development effort, he argued, “any resemblance between our flow charts and the present program is purely coincidental.”[@Knuth:1963fg]
All of these critiques are, of course, the basis of the humor in the *Datamation* cartoon: as every programmer knew well, although in theory the flowchart was meant to serve as a design document, in practice they often served only as post-facto justification. Frederick Brooks denied that he had ever known “an experienced programmer who routinely made detailed flow charts before beginning to write programs,” suggesting that “where organization standards require flow charts, these are almost invariably done after the fact.” And in fact, one of the first commercial software packages, Applied Data Research’s Autoflow, was designed specifically to reverse-engineer a flowchart “specification” from already-written program code. In other words, the implementation of many software systems actually preceded their own design! This indeed is a wonderful joke, or at the very least, a paradox. As Marty Goetz, the inventor of Autoflow recalled “like most strong programmers, I never flowcharted; I just wrote the program.” For Goetz, among others, the flowchart was nothing more than a collective fiction: a requirement driven by the managerial need for control, having nothing to do with the actual design or construction of software. The construction of the flowchart could thus be safely left to the machine, since no-one was really interested in reading them in the first place. Indeed, the expert consensus on flowcharts seemed to accord with the popular wisdom captured by the “Programmer’s Coloring Book”: there were such things as flowcharts, and they were generally wrong.
Original Sin! Computer Dating on National Geographic
National Geographic has produced an excellent series on the history of sex and sexuality. As part of that series, they ran an episode on sex and technology. If you watch closely, you can see me talking about the history of computer dating as first described on this post on this blog!
Beards, Sandals, and Programmers
At long last my article “Beards, Sandals, and Other Signs of Rugged Individualism”: Masculine Culture within the Computing Professions has been published in Osiris, the annual journal of the History of Science Society. This piece has been a long time coming: the original workshop it was commissioned for was held in 2012, and the extensive process of peer review that makes Osiris issues so special stretched out over the past two years.
The focus of the special issue is on “scientific masculinities,” and my article explores the flip-side of the work I have been doing on the history of women in computing. That is to say, my emphasis is on how male programmers constructed both a professional and a masculine identity for themselves.
From the abstract of the article:
Over the course of the 1960s and 1970s, male computer experts were able to successfully transform the “routine and mechanical” (and therefore feminized) activity of computer programming into a highly valued, well-paying, and professionally respectable discipline. They did so by constructing for themselves a distinctively masculine identity in which individual artistic genius, personal eccentricity, antiauthoritarian behavior, and a characteristic “dislike of activities involving human interaction” were mobilized as sources of personal and professional authority. This article explores the history of masculine culture and practices in computer programming, with a particular focus on the role of university computer centers as key sites of cultural formation and dissemination.
The title of the article comes from a contemporary essay by Richard Brandon called “The Problem in Perspective” (the problem here being the pervasive “question of professionalism” in the computer industry, which is the subject of my first published academic article). The “programmer type,” according to Brandon, was “excessively independent,” often to the point of mild paranoia. He was “often egocentric, slightly neurotic, and he borders upon a limited schizophrenia. The incidence of beards, sandals, and other symptoms of rugged individualism or nonconformity are notably greater among this demographic group.” Tales about programmers and their peculiarities “are legion,” Brandon argued, and “do not bear repeating here.”1 Richard Brandon, “The problem in perspective,” in Proceedings of the 1968 23rd ACM National Conference (New York, 1968): 332–334.
Having just given a talk at the SXSW interactive festival, I can attest (anecdotally, at least) that beards are alive and well in programming culture. And according to this research by the folks at Trestle Technology, which combines Github data with Microsoft facial recognition software, Swift developers are “beardy hipsters.”
Shortly after the publication of the new article, a friend discovered an extended quote from Brandon that also claimed the “two of the hippie leaders at Haight-Ashbury were computer programmers.” It took me some time to track this claim down, but I finally found it in a chapter on “The Economics of Computer Programming” that Brandon published in a 1970 book On the Management of Computer Programmers.[2. George Weinwurm, editor. On the Management of Computer Programmers (New York, Auerbach Publishers, 1970).
The association between computer culture and the counter culture has been much discussed (most sensibly and thoroughly by Fred Turner in his masterful From Counter-Culture to Cyberculture). This quote by Brandon is an early and atypical reference to hippies and hackers, and my thanks to Dag Spicer at the Computer History Museum for bringing it to my attention.
- 1Richard Brandon, “The problem in perspective,” in Proceedings of the 1968 23rd ACM National Conference (New York, 1968): 332–334.
The Context for the Programmer’s Coloring Book
One of my favorite primary sources for the Computer Boys book was the Programmer’s Coloring Book. In fact, I recently used a cartoon from that series for a forthcoming article in Information & Culture that I wrote about the history of the software flowchart.
It is only recently, however, that I learned about the larger popularity of adult coloring books (no, not that kind of “adult”…). in the 1960s. Laura Marsh at the New Republic has a brilliant new article on The Radical History of 1960s Adult Coloring Books (in which she references this site). I wish that I had been aware of this a few years ago!